

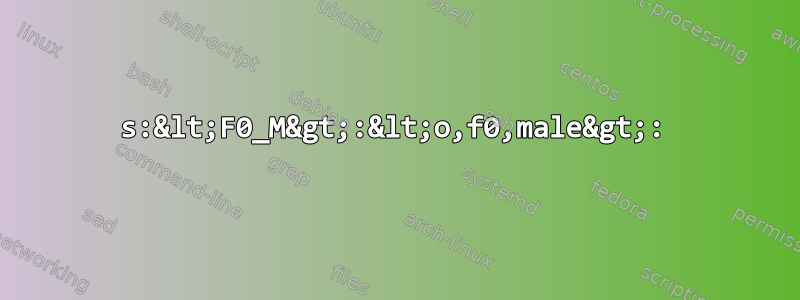
sed 명령과 함께 사용되는 다음 스크립트의 실제 기능이 무엇인지 알고 싶습니다.
sed -e 's:<F0_M>:<o,f0,male>:' \
-e 's:<F0_F>:<o,f0,female>:' \
-e 's:([0-9])::g' \
-e 's:<sil>::g' \
-e 's:([^ ]*)$::' | \
첫 번째와 두 번째 스크립트 는 텍스트 유형 <F0_F>을 <o,f0,female>. '::','g' and '$'대부분의 문서에서는 대부분의 스크립트에서 "\" 및 "/"를 사용합니다. 하지만 여기서는 ':'슬래시 대신 슬래시를 사용했습니다 . 누군가 위의 세 가지 스크립트를 설명해 주실 수 있나요?
답변1
기준구분 기호sed명령에 사용되는 것은 /다음과 같은 명령과 같습니다.
sed -e s/foo/bar/g < input > output
그러나 s명령 뒤에 다른 문자가 오는 경우에는저것해당 특정 표현의 구분 기호가 됩니다.
/구분 기호 자체가 명령에 나타나야 하는 경우 구분 기호가 아닌 문자를 사용하는 것이 일반적이므로 주의가 필요합니다.도망가다. 예를 들어 /Unix 경로를 처리하는 스크립트에서 구분 기호를 처리하는 것은 짜증나는 일입니다.
여기서는 그렇지 않은 것 같으므로 명령 작성자가 :명령의 구분 기호로 이를 선호했다고 가정합니다 sed.
명령에는 다섯 가지 표현이 있습니다.
s:<F0_M>:<o,f0,male>:
<F0_M>이렇게 하면 각 입력 줄의 첫 번째 인스턴스가 <o,f0,male>출력의 첫 번째 인스턴스로 대체됩니다. 해당 행에 대한 입력에 일치 항목이 여러 개 있는 경우 후속 일치 항목이 유지됩니다.
작은따옴표는 단순히 쉘이 표현식의 문자를 해석하지 못하도록 방지합니다. 둘 다 문자 그대로 sed명령에 전달됩니다.
s:<F0_F>:<o,f0,female>:
위의 상황과 유사하게, 명백히 이성을 겨냥한 것일 뿐입니다.
s:([0-9])::g
입력 줄에서 괄호 안의 단일 숫자를 모두 제거합니다.
이전 두 표현식과 달리 이 표현식은 후행이 g"전역"을 의미하므로 각 행의 모든 인스턴스에 영향을 미칩니다.
한 자리 숫자로만 작동합니다. (42)예를 들어, 에서는 아무 작업도 수행하지 않습니다.
s:<sil>::g
<sil>출력을 작성할 때 각 입력 줄에서 모든 인스턴스를 제거하십시오.
s:([^ ]*)$::
줄 끝에 공백이 없으면 줄 끝에 있는 대괄호 문자가 제거됩니다. 또한 줄 끝에 있는 빈 대괄호 쌍을 제거합니다.
sed이러한 주제 와 정규 표현식 에 관한 전체 책이 있습니다 . 단일 답변은 전체 주제를 학습하는 데 실제로 적합하지 않습니다.
위의 표현식은 실제로 이 점에서 조금 더 까다롭습니다. $정규식(또는 줄여서 regex)을 줄의 끝과 ^줄의 시작 부분에 고정하지만 ^해당 표현식의 의미는 다릅니다.
나는 당신이 읽을 것을 제안합니다정규식 마스터하기저자: 제프리 프리델.